浅谈Redis
为什么是6379
Redis 由意大利人Salvatore Sanfilippo(萨尔瓦多·桑菲利波普,网名 Antirez) 开发,但他已经辞去 Redis 项目开发者和维护者的角色。因为对于Antirez 来说,编程是表达自我的方式,一种艺术形式。但当软件被大规模采用时,必须做出许多妥协,这使得他陷入艺术与实用之间的两难境地,所以他渴望回归作为艺术家的身份,创造纯粹的编程艺术。后来Antirez写了一本关于人工智能的科幻小说《Wohpe》,写作的同时,也开始为大众科普技术以及做些有趣的开源作品。`
6379是MERZ在九宫格输入法上对应的号码,而MERZ取自意大利歌舞女郎Alessia Merz的名字,她经常在电视上说些愚蠢的话,所以被Antirez和他的朋友拿来作为调侃使用。但后来,随着时间的推移,其含义发生了变化,MERZ也表示具有特定技术价值的愚蠢行为。

一些应用
消息队列
我们平时习惯于使用 RabbitMQ 和 Kafka 作为消息队列中间件,来给应用程序之间增加 异步消息传递功能。这两个中间件都是专业的消息队列中间件, 特性非常多,同时使用起来也是相对比较繁琐。
我们也可以利用Redis的List数据结构作消息队列,但是它不是专业消息队列,没有ack保证等机制,所以如果对消息的可靠性有着比较高的需求的场景下,它是不适合使用的,还是建议使用专业的消息队列。
异步消息队列使用,通常使用List结构的rpush/lpush操作入队列, 使用lpop和rpop来出队列。
1 | > rpush notify-queue apple banana pear |
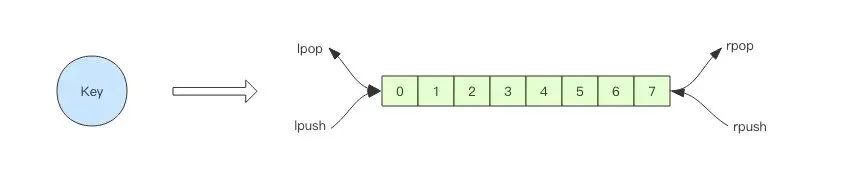
问题:如果队列中空了,会有什么问题?
如果队列空了,客户端就会陷入pop的空循环,不停地pop,没有数据,接着再pop,又没有数据。这样的空轮询不但拉高了客户端的CPU,Redis的QPS也会被拉高,非常影响性能。
解决1: 当客户端pop的时候,如果没有数据,让线程睡一会儿。这样就可以解决这样的问题,但是这样不好的问题就是会造成延迟,如果有多个消费者,那延迟就会提高,因为每个消费者之间的睡眠时间是岔开的。
解决2: 使用redis提供的blpop/brpop来读,b表示blocking(阻塞读),阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。
位图bitmap(用户签到)
在我们平时开发过程中,会有一些 bool 型数据需要存取,比如用户一年的签到记录,签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户上亿的时候,需要的存储空间是惊人的。
为了解决这个问题,Redis 提供了位图数据结构,这样每天的签到记录只占据一个位,365 天就是 365 个位,46 个字节 (一个稍长一点的字符串) 就可以完全容纳下,这就大大节约了存储空间。
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 等将 byte 数组看成「位数组」来处理。
当我们要统计月活的时候,因为需要去重,需要使用 set 来记录所有活跃用户的 id,这非常浪费内存。
这时就可以考虑使用位图来标记用户的活跃状态。每个用户会都在这个位图的一个确定位置上,0 表示不活跃,1 表示活跃。然后到月底遍历一次位图就可以得到月度活跃用户数。
这个类型不仅仅可以用来让我们改二进制改字符串值,最经典的就是用户连续签到。
key 可以设置为 前缀:用户id:年月 譬如 setbit sign:123:1909 0 1
代表用户ID=123签到,签到的时间是19年9月份,0代表该月第一天,1代表签到了
第二天没有签到,无需处理,系统默认为0
第三天签到 setbit sign:123:1909 2 1
可以查看一下目前的签到情况,显示第一天和第三天签到了,前8天目前共签到了2天
1 | 127.0.0.1:6379> setbit sign:123:1909 0 1 |

HyperLogLog(UV/日活)
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。
统计UV,就不能那么来了,因为要去重,同一个用户一天之内的多次访问请求只能计数一次。这就 要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。 去重?那就可以使用SET集合来实现了,当用户一个请求过来,使用 sadd 将用户 ID 塞进去就可 以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据 。这样确实可以实现,但是过于浪费存储空间,如果用户体量很大,空间浪费严重。而且这种统计数据的情况,不一定要那么精确,只是用来做个直观的感受,有些误差是可以被接受的。
HyperLogLog(HLL) 算法是一种估算海量数据基数的方法,它使用12k 的存储内存空间,可以统计 2^64 个元素,并提供 0.81% 的标准错误。提供了两个指令 pfadd 和 pfcount,根据字面意义很好理解,一个是增加计数,一个是获取计数。pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用户 ID 塞进去就是,pfcount 和 scard 用法是一样的,直接获取计数值。
1 | 127.0.0.1:6379> pfadd codehole user1 |
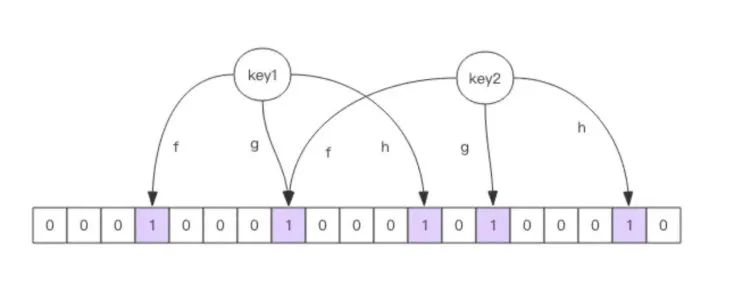
布隆过滤器(去重/垃圾过滤)
HyperLogLog 数据结构来进行估数,它非常有价值,可以解决很多精确度不高的统计需求。
但是如果我们想知道某一个值是不是已经在 HyperLogLog 结构里面了,它就无能为力了,它只提供了 pfadd 和 pfcount 方法,没有提供 pfcontains 这种方法。
讲个使用场景,比如我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的?
你会想到服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。问题是当用户量很大,每个用户看过的新闻又很多的情况下,这种方式,推荐系统的去重工作在性能上跟的上么?
1 | 127.0.0.1:6379> bf.add codehole user1 |
布隆过滤器的initial_size估计的过大,会浪费存储空间,估计的过小,就会影响准确率,用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出估计值很多。
布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场合,error_rate设置稍大一点也无伤大雅。比如在新闻去重上而言,误判率高一点只会让小部分文章不能让合适的人看到,文章的整体阅读量不会因为这点误判率就带来巨大的改变。
在爬虫系统中,我们需要对 URL 进行去重,已经爬过的网页就可以不用爬了。但是 URL 太多了,几千万几个亿,如果用一个集合装下这些 URL 地址那是非常浪费空间的。这时候就可以考虑使用布隆过滤器。它可以大幅降低去重存储消耗,只不过也会使得爬虫系统错过少量的页面。
布隆过滤器在 NoSQL 数据库领域使用非常广泛,我们平时用到的 HBase、Cassandra 还有 LevelDB、RocksDB 内部都有布隆过滤器结构,布隆过滤器可以显著降低数据库的 IO 请求数量。当用户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后再去磁盘进行查询。
邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮件目录中,这个就是误判所致,概率很低。
GEO(搜附近)
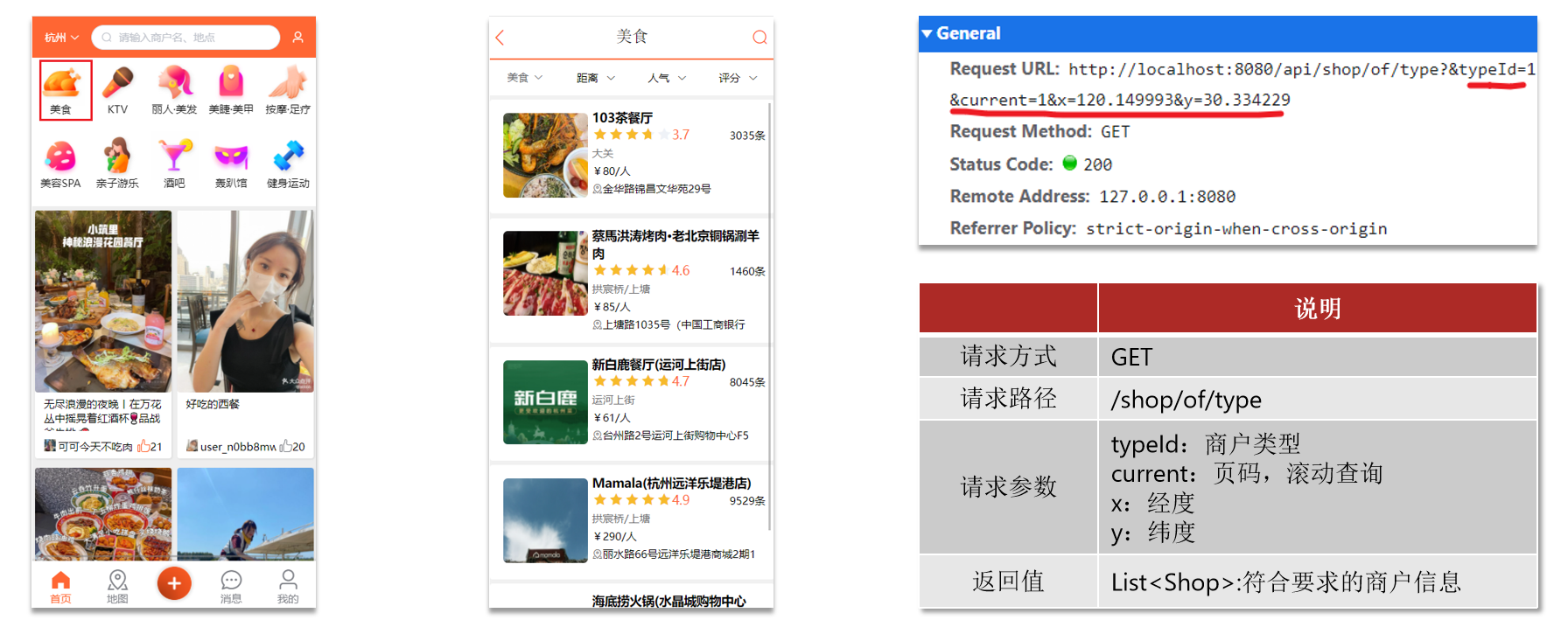
按照商户类型做分组,类型相同的商户作为同一组,以 typeId 为 key 存入同一个 GEO 集合中即可。
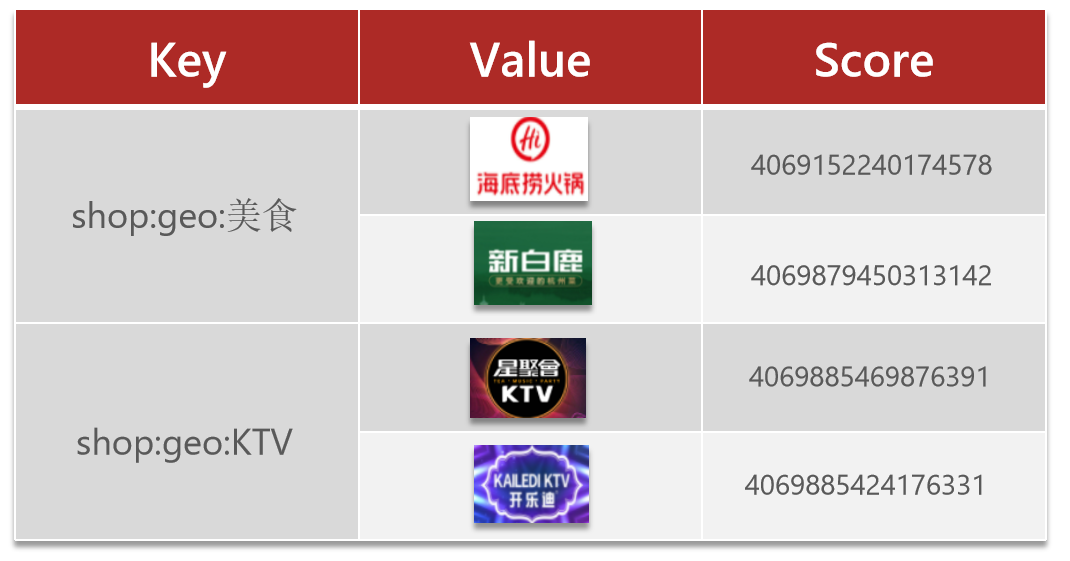
GEO 就是 Geolocation 的简写形式,代表地理坐标。Redis 在 3.2 版本中加入了对 GEO 的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。
1 | # 添加几个地理位置的坐标 |
GEO底层采用Sorted Set来实现,key存储元素信息,value存储经纬度信息(即:权重分数)
geohash 实现:
- 将经纬度转换为长度为52位的整数,作为ZSET的score。
- geohash 是一种将地理位置编码为字符串的方法,它将二维的经纬度转换为一维的字符串,从而可以用于比较距离。
- Redis 将 geohash 作为 ZSET 的 score,地点 member 作为 key 存储。
Redis 的 GEO 功能通过 ZSET 实现,其中的 geohash 用于将二维坐标转换为一维字符串,以便存储和查询。
向量搜索(数据相似性,人脸识别,文档建议)
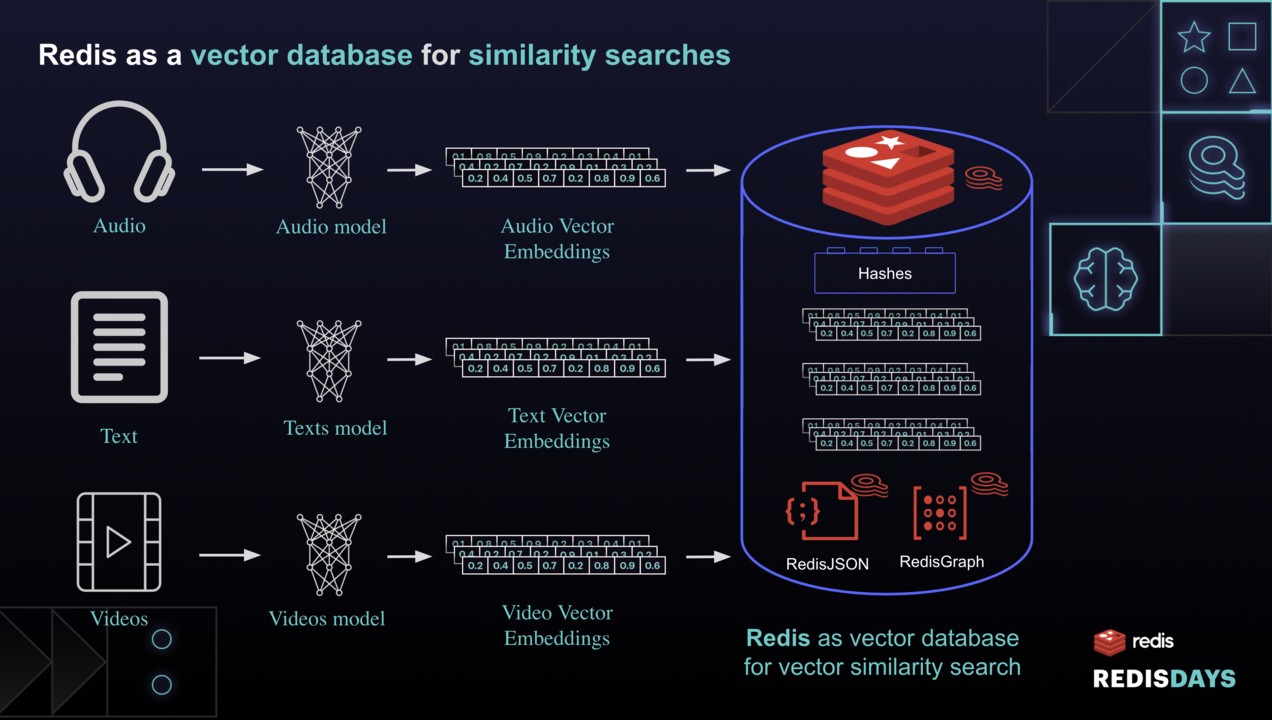
RediSearch是一个 Redis 模块,执行混合查询,将矢量相似性与传统的 RediSearch 过滤功能相结合,用于 GEO、NUMERIC、TAG 或 TEXT 数据。电子商务环境中混合查询的一个常见示例是“查找与给定查询图像外观相似的商品,但仅限于 GEO 位置和价格范围内的商品”。
- 高性能:Redis将数据存储在内存中,使得读写速度非常快,能够满足实时查询和分析的需求。
- 灵活的数据结构:Redis支持多种数据结构,能够灵活地适应不同形式的向量数据。
- 强大的查询功能:Redis提供了丰富的查询命令,能够高效地执行向量相似性查询和计算。
- 数据持久化:Redis支持多种数据持久化策略,如RDB和AOF,保证了数据的可靠性和可用性。
- 内存限制:由于Redis将数据存储在内存中,因此其容量受到物理内存的限制。对于大规模向量数据,可能需要考虑分布式存储方案。
- 数据更新:向量数据通常需要频繁地更新,这可能会对Redis的性能产生影响。因此,在设计系统时需要充分考虑数据更新的频率和方式。
文章作者:米兰
原始链接:https://blog.milanchen.site/posts/share-redis.html
版权声明:转载请声明出处