我的AI Coding实践分享
以下是我在团队中分享的文稿,分享目的是公司希望大家积极利用工具进行AI Coding,听众包括产品、UI、开发、测试等。
开场
大家好,今天分享一下我个人在日常工作中使用 AI 辅助编程的一些实践和心得。
先说一个前提:AI 发展太快了,今天聊的工具和方法,可能过几个月就有更好的替代方案。 所以今天不是在推”最佳实践”,更多是抛砖引玉——我踩了哪些坑、摸索出了什么方法、觉得什么好用,供大家参考和讨论。
分享四块内容:
1 | 1. 工具箱 —— 我在用什么 |
工具箱
先简单过一下我目前在用的工具,按场景分类:
工具全景
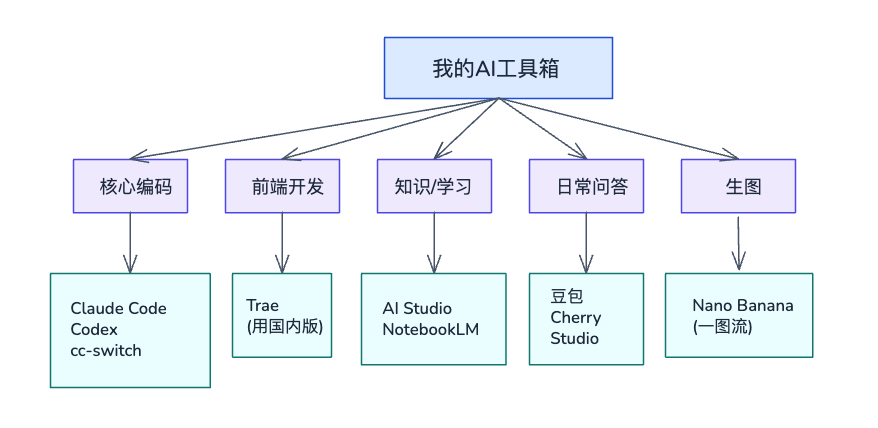
核心编码:两条 CLI 并行
| 工具 | 定位 | 说明 |
|---|---|---|
| Claude Code | CLI | 工程化最好的AI Coding Agent,但是纯血版贵、容易被封号。搭配国产模型使用。 |
| Codex | CLI | 价格合适,思考回复慢些、但是回复质量很稳。作为目前的主力使用。 |
| cc-switch | 配置管理 | 管理 MCP、Skills、系统提示词、切换模型端点,一套配置多模型复用 |
两个 CLI 工具都可以在 IDEA 中直接打开终端窗口使用,不需要离开 IDE,方便掌控改动。
其他场景
| 场景 | 工具 | 说明 |
|---|---|---|
| 前端开发 | Trae | 字节跳动的 AI IDE,目前国内版免费,前端项目开发会用它 |
| 知识学习 | Google AI Studio | 偶尔用,问答、试新模型 |
| 生图 | Google Nano Banana | 一图流生图 |
| 知识整合 | Google NotebookLM | 知识学习、信息整合和输出,做 PPT 很好用 |
| 日常问答 | 豆包 | 快速问问题,当做百度用 |
| 模型对比 | Cherry Studio | 同一个问题让不同模型回答,直观对比。还能同步对话到远程笔记(Notion、语雀等) |
当前 AI 发展极快,同类工具有很多,也没有“标准工具栈”。每个人按照需求与习惯,选择称手的就好。
AI Coding工作流
这是今天的重点部分。
先看整体:三种模式按复杂度选择
我不是所有任务都用同一套流程。根据任务的复杂度,我会选择不同的模式:
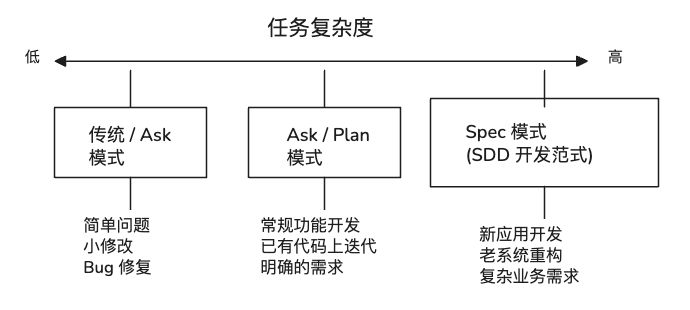
- 古法/Ask 模式:遇到一个小问题、一个小改动,直接问,直接改,不需要额外流程。
- Ask/Plan 模式:常规的功能开发,先让 AI 理解上下文和需求,用 plan 模式让它先出方案,确认后再执行。
- Spec 模式:新项目从零开始、老系统大重构——这类任务如果直接上手写,很容易跑偏。需要先定规范,再写代码。
前两种大家应该比较熟悉了,重点聊第三种。
SDD:Spec-Driven Development(规范驱动开发)
为什么需要 SDD?
大部分人用 AI 编程的流程大概是这样的:
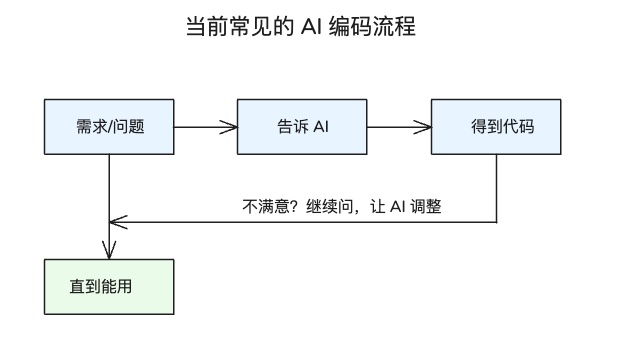
小任务这样没问题。但任务一复杂,问题就来了:
| 问题 | 表现 |
|---|---|
| 需求理解偏差 | 花了几个小时”调教”Prompt,AI 产出的代码还是不对 |
| 对话越长越跑偏 | 聊到后面,AI “失忆”了,前面定好的东西后面全忘了 |
| 过度设计 | 你要一个简单功能,它给你搞了一套过度复杂的架构 |
| 多人/多模型难协同 | 你和同事用不同的 AI 工具,上下文传递靠复制粘贴 |
SDD 的核心思路很简单:先写规范,再写代码。
SDD 的三个核心理念

工具:OpenSpec
我在接触的SDD工具是 OpenSpec,它提供了一套”提案 → 审查 → 实现 → 归档“的标准流程。
选它的原因:轻量(CLI 注入即可)、不绑定特定 AI 工具、变更可追溯。
同类工具还有Spec-Kit、BMAD、Superpowers等,思路相通,选顺手的就行。
OpenSpec 的工作流程
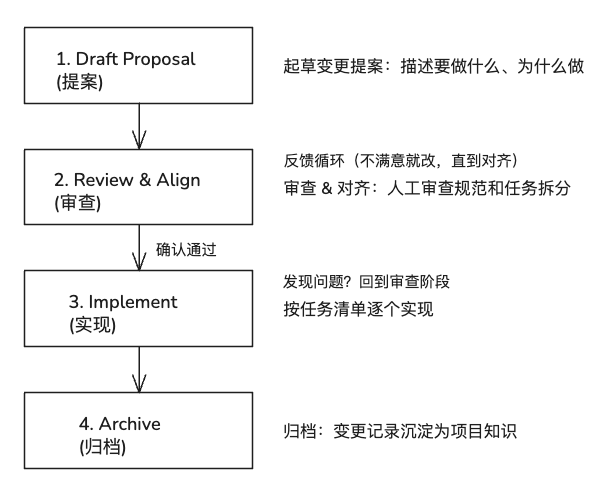
OpenSpec 生成的项目文件结构
安装 OpenSpec 后,它会在项目中创建如下目录结构。这些文件就是你项目的”规范中心”:
1 | your-project/ |
为什么这套东西对团队有价值?
| 场景 | 没有 Spec | 有 Spec |
|---|---|---|
| 他人接手项目 | 看代码猜意图 | 读 specs/ 和 archive/ 就懂 |
| 换一个 AI 工具 | 重新从头描述需求 | 同一份 Spec,换个模型接着干 |
| 需求变更 | 口头传达,改完没记录 | changes/ 里有提案、审查、归档 |
| 多人协作 | 每人理解不一样 | 大家基于同一份 Spec 对齐 |
| 回顾为什么这样设计 | 记不清了 | 查 archive/,当时的决策都在 |
| AI 上下文清空后 | 从头描述一遍需求 | AI 重读 specs/ + config.yaml |
核心观点:Spec 文件不仅仅是给 AI 看的”提示词”,它同时也是项目文档、变更记录和团队协作的契约。
用 SDD,你写的不只是代码,还有可追溯的上下文。
个人经验
以下是我自己踩过坑之后总结的一些经验,不一定对所有人适用,但供参考。
Prompt 要具体:告诉它做什么、不做什么、以及为什么
1 | ❌ 模糊的 Prompt:"优化这个接口的性能" |
- 告诉它不要做什么,比”告诉它要做什么”有时候更重要
- 给出为什么,AI 理解了原因,才能做出更合理的判断
AGENTS.md / CLAUDE.md 要精简
1 | ❌ 不好的写法:“写好的代码、注意性能、代码要规范“ |
关键原则:仅在反复出现同类问题时,才往里加规则,带上原因。 不要预设一大堆”可能有用”的规则,那样反而会稀释重要信息。
Claude Code 的配置也是同样的思路——把经验沉淀成规则,但保持精简。
上下文管理:30-40% 就该警惕了
1 | 上下文使用量 |
这也是为什么 SDD 有价值——规范文件就是你的”外部记忆”。即使上下文清空了,AI 重新读一遍 Spec 就能接上。
及时 Commit,善用 Git
1 | 一个功能做完 ──► 立即 commit |
强模型做决策,弱模型做执行
1 | 强模型 弱/快模型 |
不要诱导,用无诱导式提问
1 | ❌ 诱导式提问 ✅ 无诱导式提问 |
只给需求,不限制方向。 让 AI 先给方案,你再选。
信息源
最后聊一下信息获取。AI 每天都在变,信息过载很严重。需要建立自己的获取信息的渠道,但不要被信息淹没。
我的信息渠道
| 渠道 | 说明 |
|---|---|
| X/公众号 | 关注领域内的大 V,一手信息最快 |
| LinuxDo 论坛 | 中文社区,讨论质量不错,实践分享多 |
| GitHub Trending | 看新工具、新项目 |
避免信息过载的几个建议
1 | 1. 不是所有新工具都要学 |
收尾
今天聊了四件事:工具选顺手的就好;复杂任务先写规范再写代码;几条实用的提示词和上下文管理经验;以及怎么跟上AI的节奏而不被淹没。
AI 的列车已经开了,重要的不是现在坐在哪个位置,而是一直在车上。 工具会变、方法会迭代,但保持学习和实践的习惯不会过时,保持良好的心态。
今天就是一个交流的起点,大家在实践中有什么好的经验或者踩过的坑,都可以一起聊聊。
谢谢大家 🙏
文章作者:米兰
原始链接:https://blog.milanchen.site/posts/my-ai-coding-practice.html
版权声明:转载请声明出处