豆包OS Agent实现原理与行业思考
架构视角:多进程协同模型
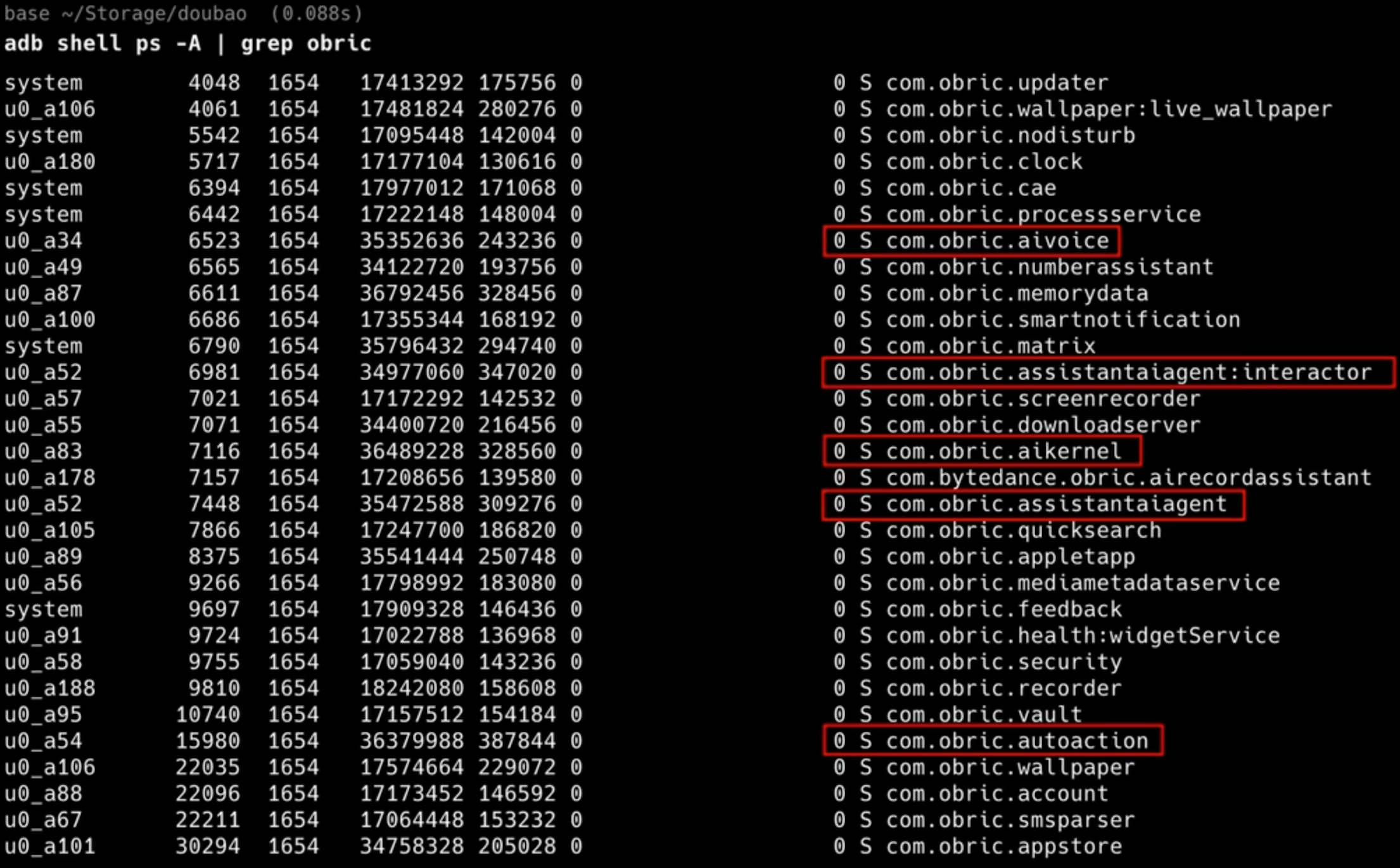
通过进程快照(ps -A | grep obric),我们可以清晰地看到 Agent 并非单体应用,而是一套严密的分层架构。这不仅是一个 App,更是一套深度集成于 Android Framework 的系统级服务。
graph TD
User[用户] -->|语音/触控| UI[交互层: assistantaiagent]
UI -->|意图识别| Kernel[推理层: aikernel]
Kernel -->|决策指令| Action[执行层: autoaction]
subgraph System_Privilege [系统特权域 - Platform Signature]
Action -->|INJECT_EVENTS| Input[输入子系统]
Action -->|READ_FRAME_BUFFER| Surface[图形子系统]
end
style Action fill:#f9f,stroke:#333,stroke-width:2px
style System_Privilege fill:#f0f0f0,stroke:#333,stroke-dasharray: 5 5
关键组件解析:
- 交互层
com.obric.assistantaiagent:用户可见的 UI 界面,负责语音交互和结果反馈。 - 推理层
com.obric.aikernel:推测为端侧小模型的运行环境,负责本地意图识别和隐私过滤。 - 执行层
com.obric.autoaction:核心差异点。拥有系统级特权(Platform Signature)的无头服务进程,负责后台执行点击与截图。
感知层:它如何“看见”屏幕?
Agent 能够操作任意 App 的前提是能够“看见”并理解当前界面。
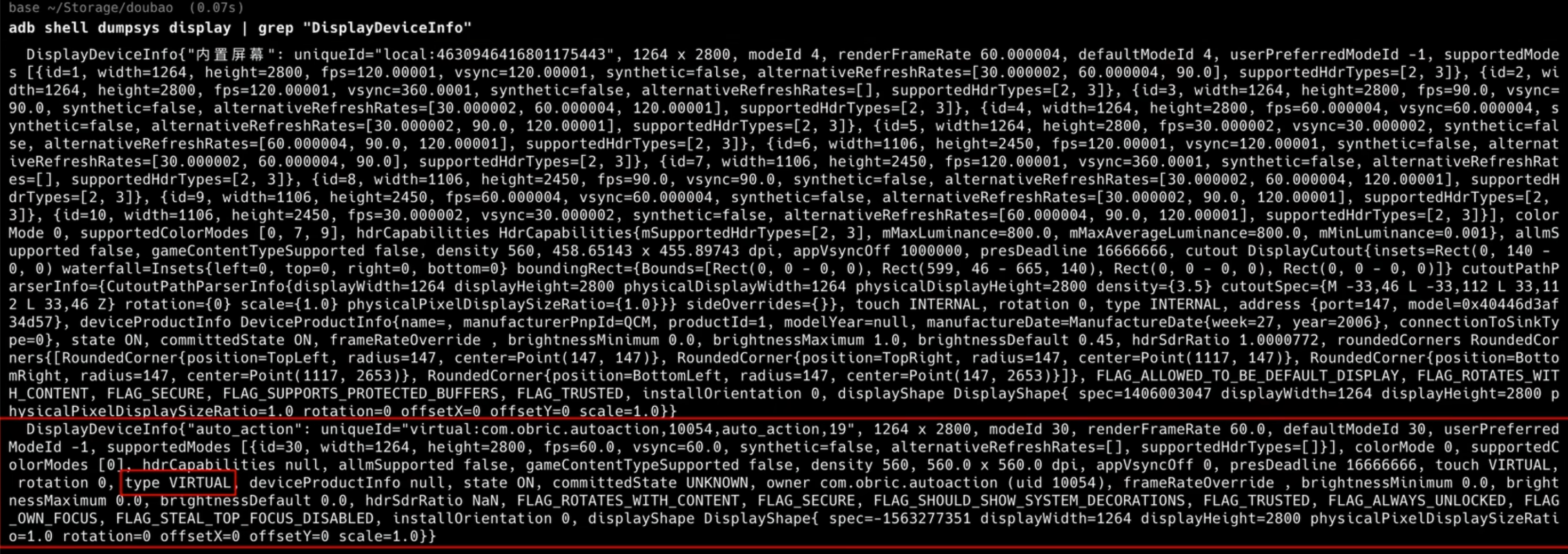
虚拟显示技术 (Virtual Display)
在 dumpsys display 日志中,Agent 利用 Android 的 VirtualDisplay 机制,在系统后台创建了一个“平行屏幕”。
graph TB
App[目标 App - 如美团] -->|绘制| Surface[SurfaceFlinger]
Surface -->|Layer Stack 0| Physical[物理屏幕 - Display 0]
Surface -->|Layer Stack 1| Virtual[虚拟屏幕 - Display 99]
Virtual -->|截屏流| VLM[Agent 视觉感知]
Input[InputManager] -->|注入事件| Virtual
Input -->|触摸事件| Physical
style Virtual fill:#ddf4ff,stroke:#0969da,stroke-width:2px
style Physical fill:#f6f8fa,stroke:#d0d7de
为何能实现“无感”:
- 显示隔离:目标 App 被投射到虚拟屏上,用户在物理屏看不到任何干扰。
- 输入隔离:Agent 通过
INJECT_EVENTS将点击事件定向注入到虚拟屏的InputChannel,不抢占物理屏焦点。
视觉数据的获取与隐私
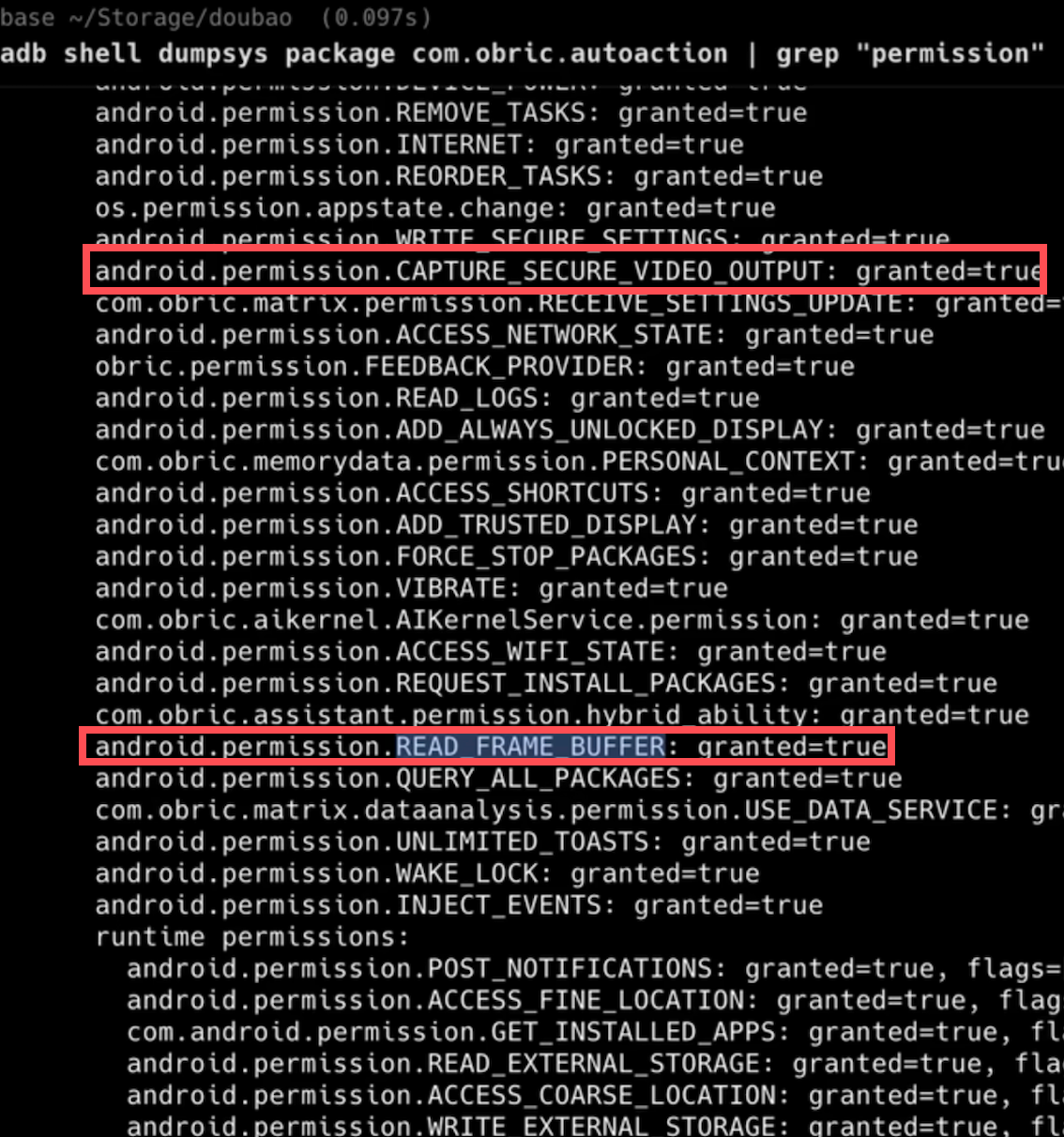
Agent 持有系统级特权权限 READ_FRAME_BUFFER,可直接访问 GPU 帧缓冲区,避免传统截图文件落地,直接读取原始位图(Raw Bitmap),效率极高。

隐私的“君子协定”:
Agent 申请了 CAPTURE_SECURE_VIDEO_OUTPUT 权限,理论上可绕过安全限制。但实际遵循 Android 的 FLAG_SECURE 协议,遇到支付或密码页面会进行黑屏处理,这是在绝对控制权与用户隐私合规之间的平衡。
决策层:端云协同的 VLM 协议
Agent 如何思考?通过网络抓包分析,还原其 “Stop-and-Think” 的思考模型。
离散轮询 vs 实时流
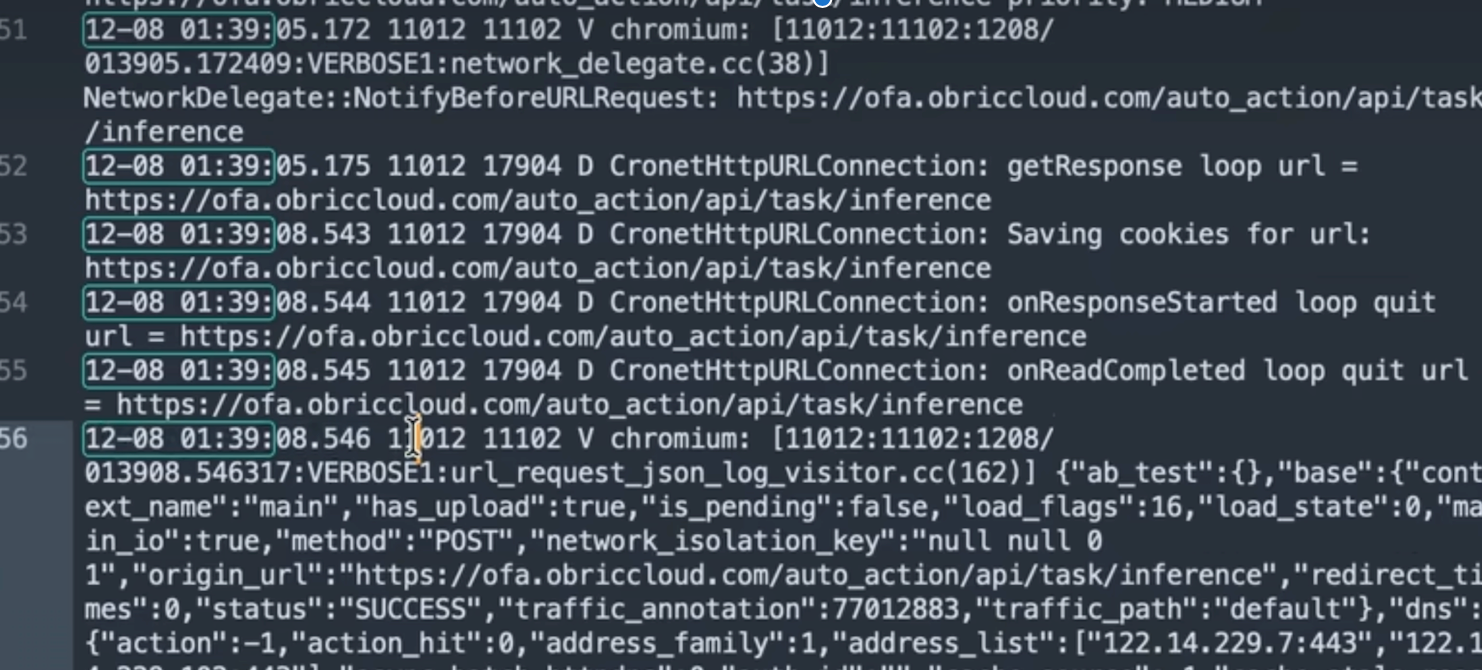
请求间隔约为 3 秒。Agent 采取“截图 -> 上传 -> 决策 -> 执行”的离散步进模式,而非上传实时视频流。
载荷分析 (Payload)
对比实际网络请求日志,证实了“本地压缩”的猜测:
- 原始 Bitmap:1080P/2K 无压缩数据,约 ~8MB/帧,延时与流量不可接受。
- 实际抓包:
sent_body_bytes显示约 ~240KB/帧,推测本地高压缩(JPEG/WebP)。
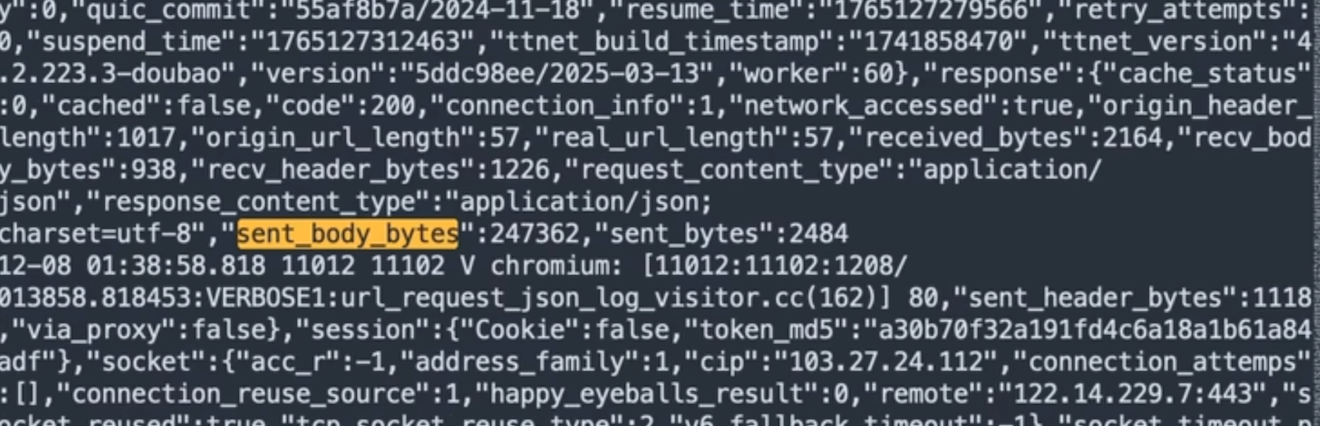
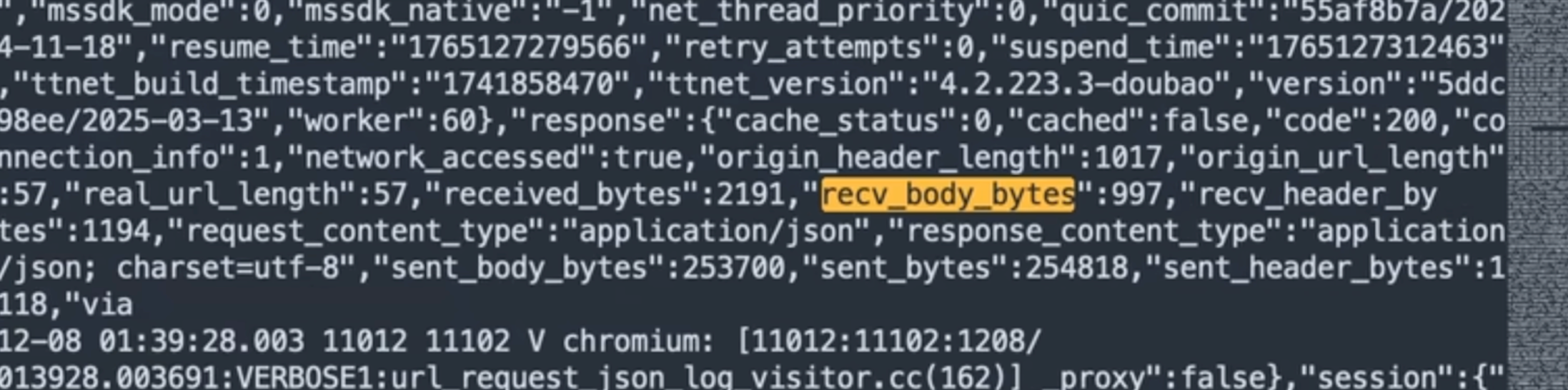
流量模型总结:这是典型的“宽上行、窄下行”。上行传输视觉信息(240KB),下行仅传输文本控制指令(1KB),网络延迟低。
原子指令集
云端 VLM 在“看图”后,返回结构化 JSON 指令:
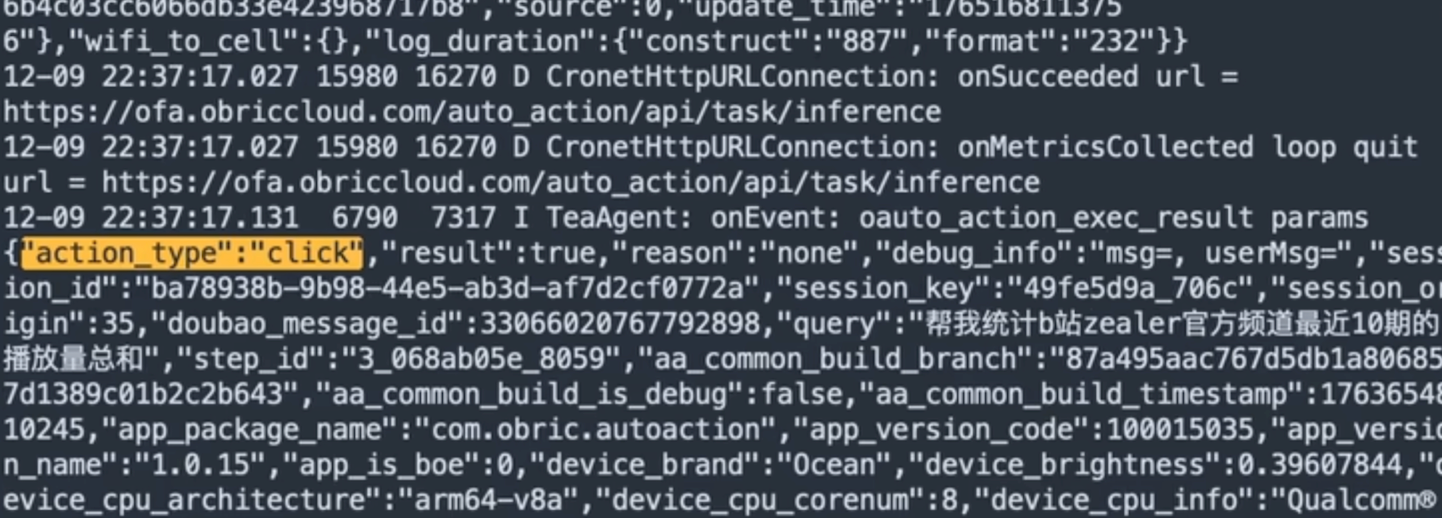
1 | { |
指令集包括:
open_app:打开应用,按包名或应用名唤起。click:坐标点击、双击、长按等。swipe:滑动。type:文本输入。device_action:系统实体键(BACK、HOME、POWER)。wait:显式等待页面加载或动画结束。get_memory:记忆读取。take_notes:信息提取到系统笔记。call_user:人工介入。stop:任务终止。
执行层:基于坐标的底层注入
这是 AI Agent 与无障碍服务最大的分水岭。
为什么必须用底层注入?
传统无障碍(Accessibility)
机制:前台独占运行。
体验:必须看着手机,用户操作会打断流程。
风控:易被检测,开启状态可被判定为“外挂”。豆包 Agent(Virtual Display)
机制:后台虚拟屏并发。
体验:真正“无感”,主屏与平行屏互不干扰。
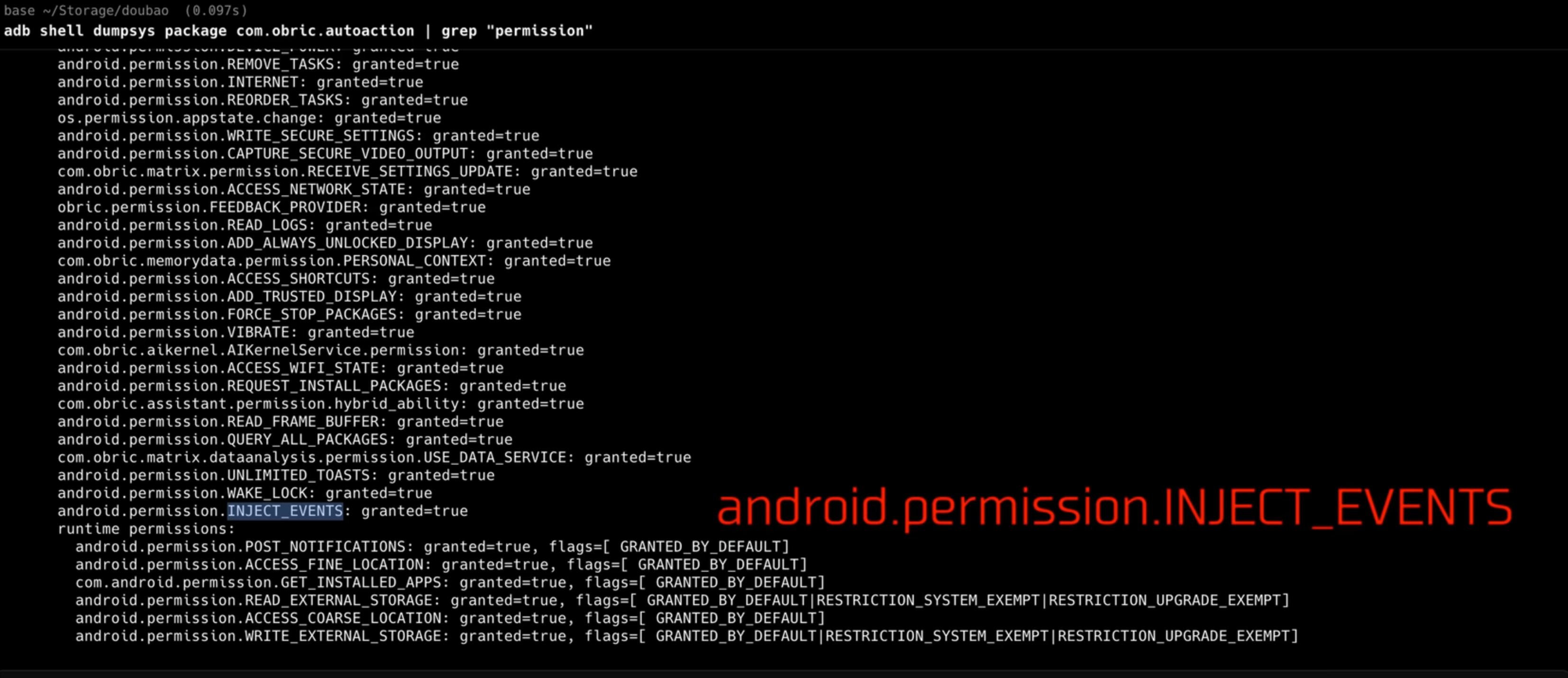
风控:隐形注入,通过INJECT_EVENTS直达输入子系统,绕过应用层检测。
隐形的手:输入注入机制
Agent 申请高权限 INJECT_EVENTS,拿到通往系统底层的“万能钥匙”。事件链路如下:
graph LR
Finger[真实手指] -->|物理触摸| Driver[触摸屏驱动]
Driver --> Input[系统输入中心 InputManager]
Agent[Agent 进程] -->|INJECT_EVENTS 指令| Input
Input -->|统一分发| App[目标 App]
style Agent fill:#ffefef,stroke:#d03030,stroke-width:2px
style Input fill:#ddf4ff,stroke:#0969da,stroke-width:2px
原理总结:Agent 绕过物理屏幕,直接在系统的输入中心插队。对于目标 App 来说,从 InputManager 收到的点击信号无论来源,数据格式一致,因此可绕过多数应用层风控。
案例还原:美团自动记账
结合日志与 Mermaid 时序图,复盘一次“美团自动记账”的端云协同过程。
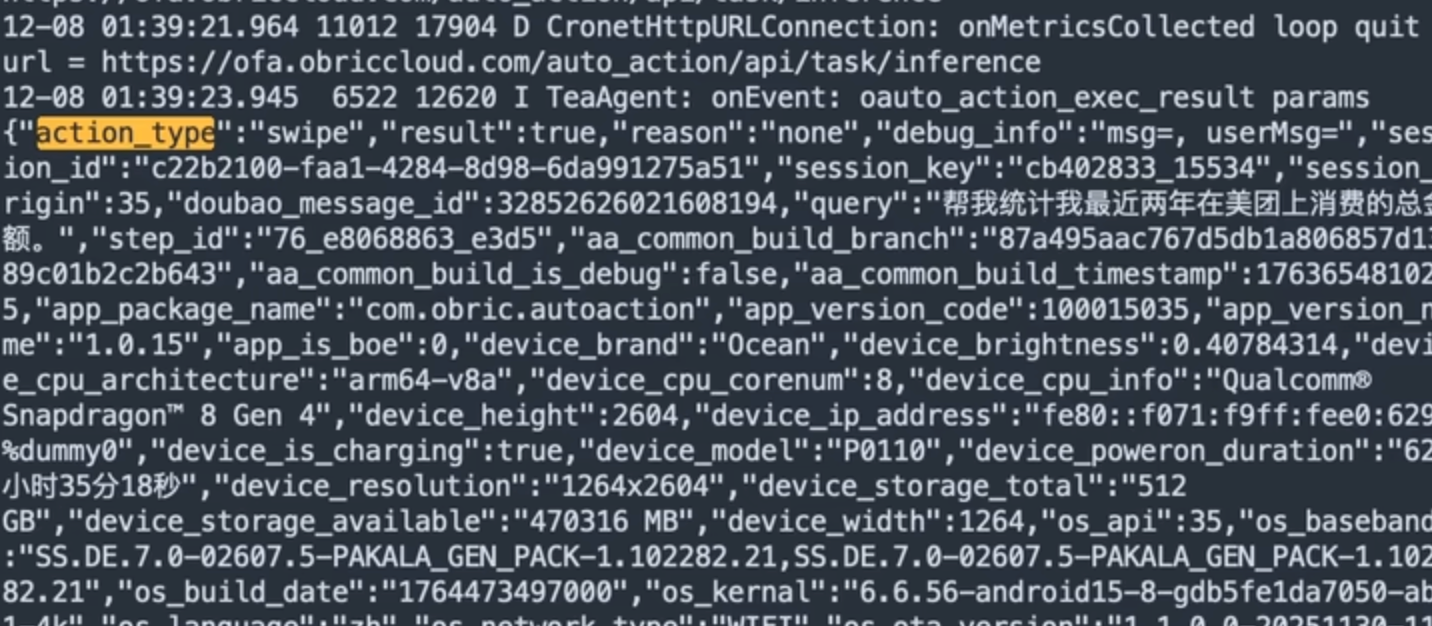
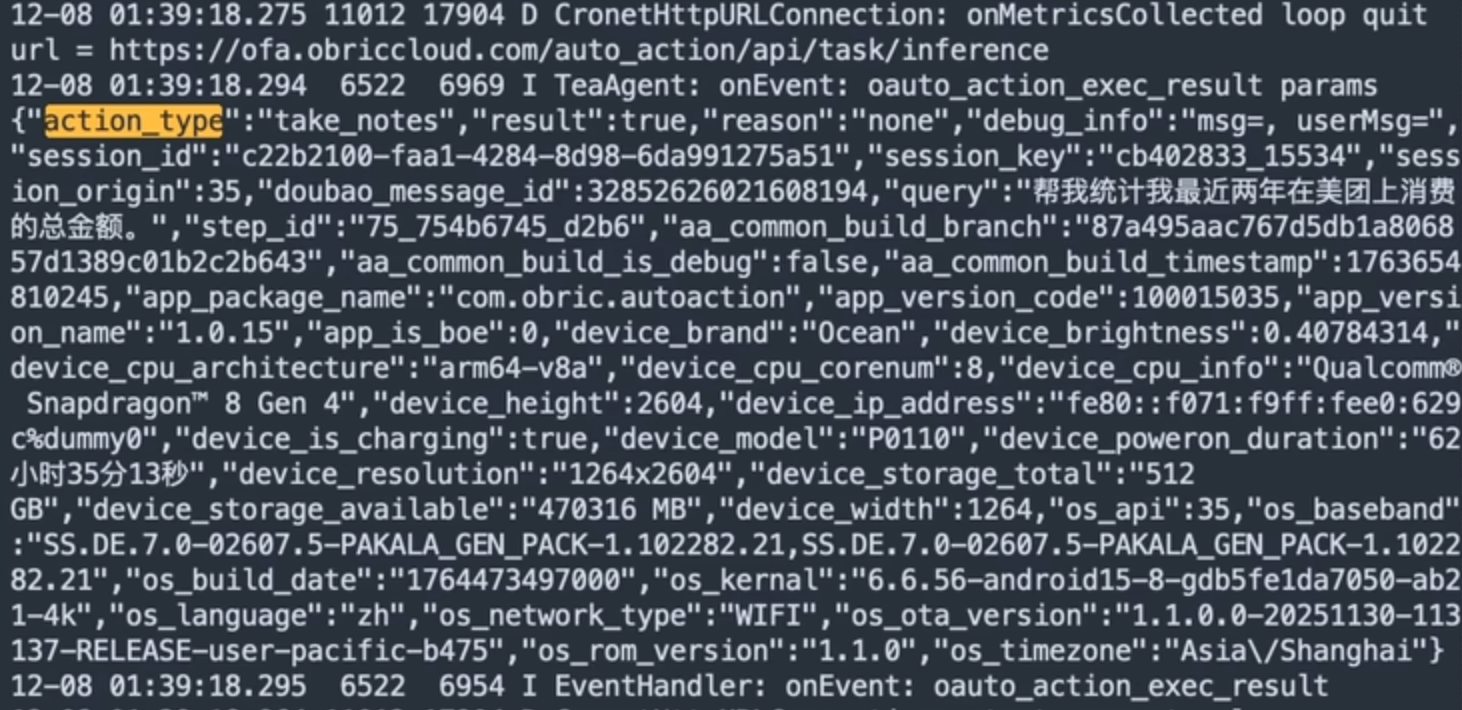
sequenceDiagram
autonumber
participant User as 用户
participant Agent as Agent - 本地
participant Cloud as VLM - 云端
participant App as 目标App
User->>Agent: 语音指令: "去美团统计消费"
loop 自动化循环 (Until Stop)
Agent->>App: 1. 捕获画面 & 压缩
Agent->>Cloud: 2. 上传截图 (240KB)
Note right of Cloud: VLM 分析画面内容...
alt 场景1: 还在桌面
Cloud-->>Agent: 指令: open_app("美团")
Agent->>App: 启动应用
else 场景2: 看到首页
Cloud-->>Agent: 指令: click("我的订单")
Agent->>App: 注入点击
else 场景3: 看到订单页
Cloud-->>Agent: 指令: swipe(下滑)
Agent->>App: 注入滑动
else 场景4: 提取消费金额
Cloud-->>Agent: 指令: take_notes("消费800元")
Agent->>Agent: 写入系统笔记
end
Agent->>App: 3. 等待渲染 (Wait)
end
Cloud-->>Agent: 指令: {"type": "stop"}
Agent->>User: 语音反馈: "本月消费 800 元"
技术演进与未来展望
虽然 Agent 实现了跨应用操作,但目前方案仍处于“初级阶段”,正面临与 App 风控体系的激烈对抗。
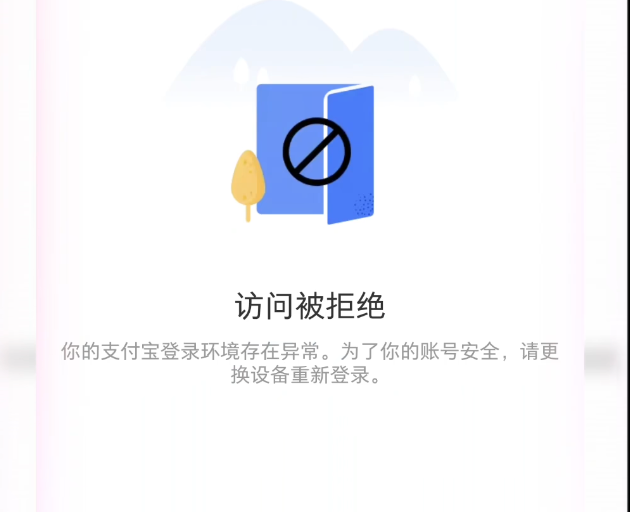
拦截背后的逻辑:这不仅是安全风控,更是生态博弈。Agent 的高效操作将 App 降维成“后台数据库”,用户不再需要浏览开屏广告与推荐流,直接触动互联网经济的核心——用户注意力,因此面临应用层强力围剿。
手机厂商破局
手机厂商拥有平台签名优势。只有系统级签名,才能合法获取 INJECT_EVENTS 与 READ_FRAME_BUFFER 等红线权限,这是第三方应用无法逾越的技术壁垒。
大势不可阻挡:AI Native OS 必然是下一代手机形态。操作系统正在从“管理 App”进化为“替用户操作 App”,交互范式将根本性变革。
未来方向
- 实时性突破:当前“截图轮询”模式(3-5 秒延迟)导致响应迟钝。需依赖端侧大模型的算力突破,将视觉识别本地化,实现人眼级实时响应。
- 标准化接口:与其用图像识别去破解界面,不如让 App 主动开放接口。App 将从“卖应用”转向“卖服务”,通过标准接口(如 Android Slices)向 OS 提供服务,实现更稳定、低耗的互联。
参考来源
文章作者:米兰
原始链接:https://blog.milanchen.site/posts/doubao-os-agent.html
版权声明:转载请声明出处